
从一个最简单的模型开始,介绍大模型是如何工作的。
大模型是如何工作的
先来讲几个名词:
token:指文本数据的最小单位。在自然语言处理任务中,一个token可以是一个单词、一个字母、一个标点符号或者其他更小的文本单位;context:上下文,指的是输入模型的文本序列。这个文本序列可以是一个句子、一个段落,甚至是更长的文本片段;vocab_size:单个 token 有多少种可能的值,例如0和1两种;context_length:上下文长度,用token个数来表示,例如 3 个 token。
开始吧。
用一个最简单的模型来讲,规定是:Token为0 和 1 ,上下文长度为 3。
那么,这个模型所有状态空间为0, 1, 00, 01, 10, 11, 000, 001, 010, 011, 100, 101, 110, 111 一共14个,计算的方法为:2^1 + 2^2 + 2^3 = 14。简化一下,如果所有状态都是满的,即context_length 为3,那么一共的可能为:000, 001, 010, 011, 100, 101, 110, 111 一共8种,计算的方法为:vocab_size^context_length = 8 。
可以将模型想象成抛硬币:
- 正面朝上表示
token=1,反面朝上表示token=0; - 新来一个
token时,将更新context:将新token追加到最右边,然后把最左边的token去掉,从而得到一个新context;
从旧的上下文(例如 010)到新的上下文(例如 101)为一次状态转移。
初始状态下,我们输入一个数,下一个是0和1的概率是差不多的,状态转移图如下。
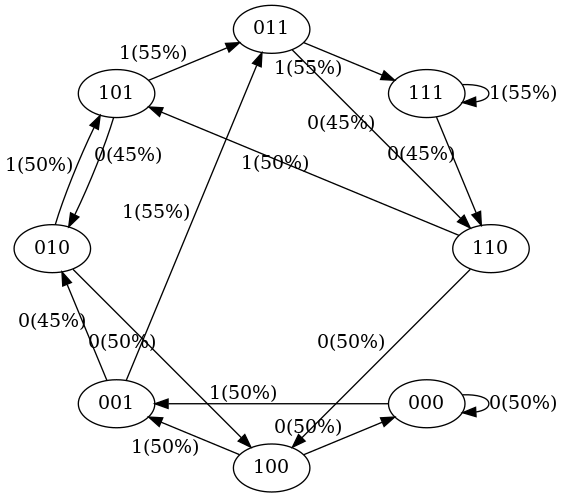
可以看到有如下几个特点:
- 在每个状态下,下一个
token只有0和1两种可能,因此每个节点有 2 个出向箭头; - 每次状态转换时,最左边的
token被丢弃,新token会追加到最右侧; - 此时的状态转移概率大部分都是均匀分布的,因为我们还没拿真正的输入序列来训练这个模型。
现在,我们使用这一串数字111101111011110进行50次训练,训练完成后,状态转移图如下。
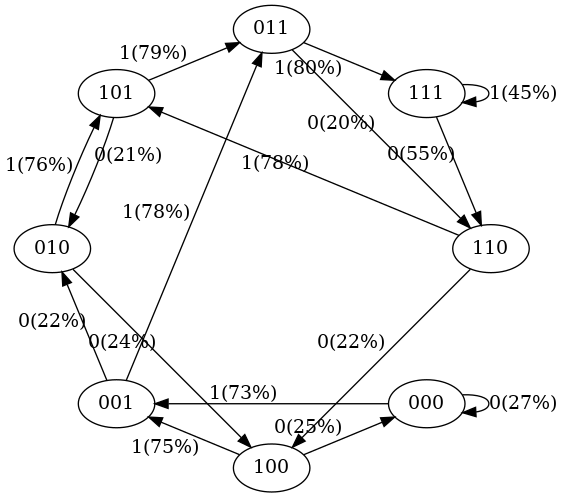
可以看到有如下几个特点:
- 在训练数据中,状态
101 -> 011的概率是 100%,因此我们看到训练之后的模型中,101 -> 011的转移概率很高; - 在训练数据中,状态
111 -> 111和111 -> 110的概率分别是 50%; 在训练之后的模型中,两个转移概率分别为 45% 和 55%,也差不多是一半一半; - 没有看到 100% 或 50% 的转移概率,这是因为没有经过充分训练,继续训练就会出现更接近这两个值的转移概率。
接下来开始测试训练后的模型,输入111 后,输出11101110111011011110101 ,而我们之前训练的序列是111101111011110 ,我们的训练的越充分,采样得到的序列就会跟训练序列越像。 但在本文的例子中,我们永远得不到完美结果, 因为状态111的下一个token是模糊的:50% 概率是1,50% 是0。
将这个例子放大无数倍(例如GPT-2 ,它的vocab_size为50k ,context_length为2k )其实就是我们使用的大模型,当然整个过程要比这个复杂得多。
如何训练一个语言大模型
先来讲几个名词:
SFT(Supervised Fine-Tuning):监督微调;RLHF(Reinforcement Learning from Human Feedback):从人类反馈中进行强化学习。
开始。
首先进行的是收集大量的数据,即语料,以Meta/Facebook训练的LLaMA模型为例,它的数据集为下表。
| 数据集(Dataset) | 占比(Proportion) | 迭代次数(Epochs) | 数据集大小(Disk size) |
| CommonCrawl | 67.0% | 1.10 | 3.3 TB |
| C4 | 15.0% | 1.06 | 783 GB |
| Github | 4.5% | 0.64 | 328 GB |
| Wikipedia | 4.5% | 2.45 | 83 GB |
| Books | 4.5% | 2.23 | 85 GB |
| ArXiv | 2.5% | 1.06 | 92 GB |
| StackExchange | 2.0% | 1.03 | 78 GB |
拿到数据后,会将内容进行预处理,即进行向量化,结合第一节中的知识,即将内容变成一个token ,一个token可能是一个单词、一个词根、标点、标点+单词等等,这种token转换是无损的,有很多算法,例如常用的字节对编码。下图是一个对句子进行向量化的例子。

英文中词汇表大小通常为10K个 token ,上下文长度各模型会有不同,但通常为 2k/4k,有时甚至 100k。根据第一节中的知识,即可算出模型的最大参数值,GPT-3 的最大参数是 175b,而 LLaMA 的最大参数只有 65b。
根据向量化后的内容开始训练,过程中,预测分布就会发生变化。开始时,权重是完全随机的,随着 训练时间越来越长,会得到越来越一致和连贯的采样输出。
训练一段时间之后,即可学会单词以及在哪里放空格和逗号等等。随着时间的推移,我们可以得到越来越一致的预测。
完成基础训练后的语言模型功能其实非常单一,它们只想要补全文档,即预测并输出下一个token,换句话说, 如果你想让它们完成其他任务,就要通过某些方式骗一下它们,让它们以为自己在补全文档。
可以采用few-shot 提示的办法来欺骗它,即将内容整理成问题和答案的形式。
问题:xxx
回答:xxx我们以提示的形式提出一个问题,它接下来做的事情仍然是它认为的补全文档, 但实际上已经回答了我们的问题。
但是,基础模型不是助手,它们不想回答问题,只想补全文档。
这样训练后的模型是否是否会输出我们期望的内容?不太确定,所以我们需要进行主动干预,主要存在两种办法,SFT(监督微调)或RLHF(强化学习)。
- SFT的主要工作内容为:人工标注员对问题给出一个理想回答,要求这些回答是有帮助的。收集数万条人工数据,进行多轮强化训练。
- RLHF的主要工作内容为:大模型对问题给出多个回答,人工标注员对结果进行排名,对排名后的数据进行强化学习,排名较高的数据在未来将获得更高的出现概率。
从人类的反馈来看,质量从高到低依次为:RLHF 模型、SFT 模型、基座模型。为什么 RLHF 效果这么好呢?一个猜测为判断比生成更容易。RLHF方式更容易落地,实操性更强。
这样,一个大概率可以输出人类理想回答的语言大模型,即可开始工作。
这样通用的大模型可以用来解决日常问题,但是对于专业内容,例如:法律、数学等通常不会有大量的语料进行训练,所以对应内容的输出效果通常很差。针对行业的具体使用场景,通常的做法是利用开源的语言模型进行增量训练,即将自己掌握的内容当作语料,在已有模型的基础上添加语料进行训练。
开源知识库大模型项目,会自动对文本数据进行预处理、向量化和 QA 分割,节省手动训练时间,提升效能,适合企业具体使用场景的大模型搭建。
用最小的资源跑通知识库大模型
接下来这里演示利用参数较小的Qwen-1.8B-Chat大模型、开源知识库项目FastGPT以及对接大模型API的开源项目One API进行本地搭建。
通义千问-1.8B(Qwen-1.8B)是阿里云研发的通义千问大模型系列的18亿参数规模的模型。Qwen-1.8B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。在Qwen-1.8B的基础上,使用对齐机制打造基于大语言模型的AI助手为Qwen-1.8B-Chat。其提供int8和int4量化版本,推理最低仅需不到2GB显存,生成2048 tokens仅需3GB显存占用。微调最低仅需6GB。
FastGPT 是一个基于 LLM 大语言模型的知识库问答系统,提供开箱即用的数据处理、模型调用等能力。同时可以通过 Flow 可视化进行工作流编排,从而实现复杂的问答场景。
One API 通过标准的 OpenAI API 格式访问所有的大模型,开箱即用 。
通义千问-1.8B搭建及使用
访问链接:https://huggingface.co/Qwen/Qwen-1_8B-Chat
要求
- python 3.8及以上版本
- pytorch 1.12及以上版本,推荐2.0及以上版本
- 建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)
开始搭建
第一步:新建文件夹、创建并进入一个虚拟环境:
mkdir Qwen-1.8B-Chat
python3 -m venv Qwen-1.8B-Chat
source Qwen-1.8B-Chat/bin/activate第二步:下载依赖项:
pip3 install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed第三步:创建启动文件并执行,新建Python文件Qwen-1.8B-Chat.py,内容为:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import gradio
import openai
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-1_8B-Chat", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B-Chat", device_map="mps", trust_remote_code=True).eval()
def answer(question):
response, history = model.chat(tokenizer, question, history=None)
return response
iface = gradio.Interface(fn=answer,
inputs="text",
outputs="text",
title="Qwen-1_8B-Chat-FastWeb")
if __name__ == "__main__":
# iface.launch(share=False)
iface.launch(share=True)代码使用了gradio库创建基础页面,要注意的是,如果你是PC电脑,请将device_map="mps"改为:device_map="gpu"或device_map="cpu"。
启动:
python3 Qwen-1.8B-Chat.py
第一次运行会下载模型文件,并使用一些Python库,如果报错直接pip3下载即可。
成功运行会创建本地链接,访问即可使用。
以上为基础模型的使用,如果想要与其他知识库大模型项目对接,需要使用openai_api定义好的接口。创建文件openai_api.py,内容为:
# coding=utf-8
# Implements API for Qwen-7B in OpenAI's format. (https://platform.openai.com/docs/api-reference/chat)
# Usage: python openai_api.py
# Visit http://localhost:8000/docs for documents.
import re
import copy
import json
import time
from argparse import ArgumentParser
from contextlib import asynccontextmanager
from typing import Dict, List, Literal, Optional, Union
import torch
import uvicorn
import tiktoken
import numpy as np
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel, Field
from sse_starlette.sse import EventSourceResponse
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers.generation import GenerationConfig
from sentence_transformers import SentenceTransformer
from sklearn.preprocessing import PolynomialFeatures
def _gc(forced: bool = False):
global args
if args.disable_gc and not forced:
return
import gc
gc.collect()
if torch.cuda.is_available():
torch.cuda.empty_cache()
@asynccontextmanager
async def lifespan(app: FastAPI): # collects GPU memory
yield
_gc(forced=True)
app = FastAPI(lifespan=lifespan)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
class ModelCard(BaseModel):
id: str
object: str = "model"
created: int = Field(default_factory=lambda: int(time.time()))
owned_by: str = "owner"
root: Optional[str] = None
parent: Optional[str] = None
permission: Optional[list] = None
class ModelList(BaseModel):
object: str = "list"
data: List[ModelCard] = []
class ChatMessage(BaseModel):
role: Literal["user", "assistant", "system", "function"]
content: Optional[str]
function_call: Optional[Dict] = None
class DeltaMessage(BaseModel):
role: Optional[Literal["user", "assistant", "system"]] = None
content: Optional[str] = None
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatMessage]
functions: Optional[List[Dict]] = None
temperature: Optional[float] = None
top_p: Optional[float] = None
max_length: Optional[int] = None
stream: Optional[bool] = False
stop: Optional[List[str]] = None
class ChatCompletionResponseChoice(BaseModel):
index: int
message: ChatMessage
finish_reason: Literal["stop", "length", "function_call"]
class ChatCompletionResponseStreamChoice(BaseModel):
index: int
delta: DeltaMessage
finish_reason: Optional[Literal["stop", "length"]]
class ChatCompletionResponse(BaseModel):
model: str
object: Literal["chat.completion", "chat.completion.chunk"]
choices: List[
Union[ChatCompletionResponseChoice, ChatCompletionResponseStreamChoice]
]
created: Optional[int] = Field(default_factory=lambda: int(time.time()))
@app.get("/v1/models", response_model=ModelList)
async def list_models():
global model_args
model_card = ModelCard(id="qwen-turbo")
return ModelList(data=[model_card])
# To work around that unpleasant leading-n tokenization issue!
def add_extra_stop_words(stop_words):
if stop_words:
_stop_words = []
_stop_words.extend(stop_words)
for x in stop_words:
s = x.lstrip("n")
if s and (s not in _stop_words):
_stop_words.append(s)
return _stop_words
return stop_words
def trim_stop_words(response, stop_words):
if stop_words:
for stop in stop_words:
idx = response.find(stop)
if idx != -1:
response = response[:idx]
return response
TOOL_DESC = """{name_for_model}: Call this tool to interact with the {name_for_human} API. What is the {name_for_human} API useful for? {description_for_model} Parameters: {parameters}"""
REACT_INSTRUCTION = """Answer the following questions as best you can. You have access to the following APIs:
{tools_text}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tools_name_text}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!"""
_TEXT_COMPLETION_CMD = object()
#
# Temporarily, the system role does not work as expected.
# We advise that you write the setups for role-play in your query,
# i.e., use the user role instead of the system role.
#
# TODO: Use real system role when the model is ready.
#
def parse_messages(messages, functions):
if all(m.role != "user" for m in messages):
raise HTTPException(
status_code=400,
detail=f"Invalid request: Expecting at least one user message.",
)
messages = copy.deepcopy(messages)
default_system = "You are a helpful assistant."
system = ""
if messages[0].role == "system":
system = messages.pop(0).content.lstrip("n").rstrip()
if system == default_system:
system = ""
if functions:
tools_text = []
tools_name_text = []
for func_info in functions:
name = func_info.get("name", "")
name_m = func_info.get("name_for_model", name)
name_h = func_info.get("name_for_human", name)
desc = func_info.get("description", "")
desc_m = func_info.get("description_for_model", desc)
tool = TOOL_DESC.format(
name_for_model=name_m,
name_for_human=name_h,
# Hint: You can add the following format requirements in description:
# "Format the arguments as a JSON object."
# "Enclose the code within triple backticks (`) at the beginning and end of the code."
description_for_model=desc_m,
parameters=json.dumps(func_info["parameters"], ensure_ascii=False),
)
tools_text.append(tool)
tools_name_text.append(name_m)
tools_text = "nn".join(tools_text)
tools_name_text = ", ".join(tools_name_text)
system += "nn" + REACT_INSTRUCTION.format(
tools_text=tools_text,
tools_name_text=tools_name_text,
)
system = system.lstrip("n").rstrip()
dummy_thought = {
"en": "nThought: I now know the final answer.nFinal answer: ",
"zh": "nThought: 我会作答了。nFinal answer: ",
}
_messages = messages
messages = []
for m_idx, m in enumerate(_messages):
role, content, func_call = m.role, m.content, m.function_call
if content:
content = content.lstrip("n").rstrip()
if role == "function":
if (len(messages) == 0) or (messages[-1].role != "assistant"):
raise HTTPException(
status_code=400,
detail=f"Invalid request: Expecting role assistant before role function.",
)
messages[-1].content += f"nObservation: {content}"
if m_idx == len(_messages) - 1:
messages[-1].content += "nThought:"
elif role == "assistant":
if len(messages) == 0:
raise HTTPException(
status_code=400,
detail=f"Invalid request: Expecting role user before role assistant.",
)
last_msg = messages[-1].content
last_msg_has_zh = len(re.findall(r"[u4e00-u9fff]+", last_msg)) > 0
if func_call is None:
if functions:
content = dummy_thought["zh" if last_msg_has_zh else "en"] + content
else:
f_name, f_args = func_call["name"], func_call["arguments"]
if not content:
if last_msg_has_zh:
content = f"Thought: 我可以使用 {f_name} API。"
else:
content = f"Thought: I can use {f_name}."
content = f"n{content}nAction: {f_name}nAction Input: {f_args}"
if messages[-1].role == "user":
messages.append(
ChatMessage(role="assistant", content=content.lstrip("n").rstrip())
)
else:
messages[-1].content += content
elif role == "user":
messages.append(
ChatMessage(role="user", content=content.lstrip("n").rstrip())
)
else:
raise HTTPException(
status_code=400, detail=f"Invalid request: Incorrect role {role}."
)
query = _TEXT_COMPLETION_CMD
if messages[-1].role == "user":
query = messages[-1].content
messages = messages[:-1]
if len(messages) % 2 != 0:
raise HTTPException(status_code=400, detail="Invalid request")
history = [] # [(Q1, A1), (Q2, A2), ..., (Q_last_turn, A_last_turn)]
for i in range(0, len(messages), 2):
if messages[i].role == "user" and messages[i + 1].role == "assistant":
usr_msg = messages[i].content.lstrip("n").rstrip()
bot_msg = messages[i + 1].content.lstrip("n").rstrip()
if system and (i == len(messages) - 2):
usr_msg = f"{system}nnQuestion: {usr_msg}"
system = ""
for t in dummy_thought.values():
t = t.lstrip("n")
if bot_msg.startswith(t) and ("nAction: " in bot_msg):
bot_msg = bot_msg[len(t) :]
history.append([usr_msg, bot_msg])
else:
raise HTTPException(
status_code=400,
detail="Invalid request: Expecting exactly one user (or function) role before every assistant role.",
)
if system:
assert query is not _TEXT_COMPLETION_CMD
query = f"{system}nnQuestion: {query}"
return query, history
def parse_response(response):
func_name, func_args = "", ""
i = response.rfind("nAction:")
j = response.rfind("nAction Input:")
k = response.rfind("nObservation:")
if 0 <= i < j: # If the text has `Action` and `Action input`,
if k < j: # but does not contain `Observation`,
# then it is likely that `Observation` is omitted by the LLM,
# because the output text may have discarded the stop word.
response = response.rstrip() + "nObservation:" # Add it back.
k = response.rfind("nObservation:")
func_name = response[i + len("nAction:") : j].strip()
func_args = response[j + len("nAction Input:") : k].strip()
if func_name:
choice_data = ChatCompletionResponseChoice(
index=0,
message=ChatMessage(
role="assistant",
content=response[:i],
function_call={"name": func_name, "arguments": func_args},
),
finish_reason="function_call",
)
return choice_data
z = response.rfind("nFinal Answer: ")
if z >= 0:
response = response[z + len("nFinal Answer: ") :]
choice_data = ChatCompletionResponseChoice(
index=0,
message=ChatMessage(role="assistant", content=response),
finish_reason="stop",
)
return choice_data
# completion mode, not chat mode
def text_complete_last_message(history, stop_words_ids, gen_kwargs):
im_start = "<|im_start|>"
im_end = "<|im_end|>"
prompt = f"{im_start}systemnYou are a helpful assistant.{im_end}"
for i, (query, response) in enumerate(history):
query = query.lstrip("n").rstrip()
response = response.lstrip("n").rstrip()
prompt += f"n{im_start}usern{query}{im_end}"
prompt += f"n{im_start}assistantn{response}{im_end}"
prompt = prompt[: -len(im_end)]
_stop_words_ids = [tokenizer.encode(im_end)]
if stop_words_ids:
for s in stop_words_ids:
_stop_words_ids.append(s)
stop_words_ids = _stop_words_ids
input_ids = torch.tensor([tokenizer.encode(prompt)]).to(model.device)
output = model.generate(input_ids, stop_words_ids=stop_words_ids, **gen_kwargs).tolist()[0]
output = tokenizer.decode(output, errors="ignore")
assert output.startswith(prompt)
output = output[len(prompt) :]
output = trim_stop_words(output, ["<|endoftext|>", im_end])
print(f"<completion>n{prompt}n<!-- *** -->n{output}n</completion>")
return output
@app.post("/v1/chat/completions", response_model=ChatCompletionResponse)
async def create_chat_completion(request: ChatCompletionRequest):
global model, tokenizer
gen_kwargs = {}
if request.temperature is not None:
if request.temperature < 0.01:
gen_kwargs['top_k'] = 1 # greedy decoding
else:
# Not recommended. Please tune top_p instead.
gen_kwargs['temperature'] = request.temperature
if request.top_p is not None:
gen_kwargs['top_p'] = request.top_p
stop_words = add_extra_stop_words(request.stop)
if request.functions:
stop_words = stop_words or []
if "Observation:" not in stop_words:
stop_words.append("Observation:")
query, history = parse_messages(request.messages, request.functions)
if request.stream:
if request.functions:
raise HTTPException(
status_code=400,
detail="Invalid request: Function calling is not yet implemented for stream mode.",
)
generate = predict(query, history, request.model, stop_words, gen_kwargs)
return EventSourceResponse(generate, media_type="text/event-stream")
stop_words_ids = [tokenizer.encode(s) for s in stop_words] if stop_words else None
if query is _TEXT_COMPLETION_CMD:
response = text_complete_last_message(history, stop_words_ids=stop_words_ids, gen_kwargs=gen_kwargs)
else:
response, _ = model.chat(
tokenizer,
query,
history=history,
stop_words_ids=stop_words_ids,
**gen_kwargs
)
print(f"<chat>n{history}n{query}n<!-- *** -->n{response}n</chat>")
_gc()
response = trim_stop_words(response, stop_words)
if request.functions:
choice_data = parse_response(response)
else:
choice_data = ChatCompletionResponseChoice(
index=0,
message=ChatMessage(role="assistant", content=response),
finish_reason="stop",
)
return ChatCompletionResponse(
model=request.model, choices=[choice_data], object="chat.completion"
)
def _dump_json(data: BaseModel, *args, **kwargs) -> str:
try:
return data.model_dump_json(*args, **kwargs)
except AttributeError: # pydantic<2.0.0
return data.json(*args, **kwargs) # noqa
async def predict(
query: str, history: List[List[str]], model_id: str, stop_words: List[str], gen_kwargs: Dict,
):
global model, tokenizer
choice_data = ChatCompletionResponseStreamChoice(
index=0, delta=DeltaMessage(role="assistant"), finish_reason=None
)
chunk = ChatCompletionResponse(
model=model_id, choices=[choice_data], object="chat.completion.chunk"
)
yield "{}".format(_dump_json(chunk, exclude_unset=True))
current_length = 0
stop_words_ids = [tokenizer.encode(s) for s in stop_words] if stop_words else None
if stop_words:
# TODO: It's a little bit tricky to trim stop words in the stream mode.
raise HTTPException(
status_code=400,
detail="Invalid request: custom stop words are not yet supported for stream mode.",
)
response_generator = model.chat_stream(
tokenizer, query, history=history, stop_words_ids=stop_words_ids, **gen_kwargs
)
for new_response in response_generator:
if len(new_response) == current_length:
continue
new_text = new_response[current_length:]
current_length = len(new_response)
choice_data = ChatCompletionResponseStreamChoice(
index=0, delta=DeltaMessage(content=new_text), finish_reason=None
)
chunk = ChatCompletionResponse(
model=model_id, choices=[choice_data], object="chat.completion.chunk"
)
yield "{}".format(_dump_json(chunk, exclude_unset=True))
choice_data = ChatCompletionResponseStreamChoice(
index=0, delta=DeltaMessage(), finish_reason="stop"
)
chunk = ChatCompletionResponse(
model=model_id, choices=[choice_data], object="chat.completion.chunk"
)
yield "{}".format(_dump_json(chunk, exclude_unset=True))
yield "[DONE]"
_gc()
def _get_args():
parser = ArgumentParser()
parser.add_argument(
"-c",
"--checkpoint-path",
type=str,
default="Qwen/Qwen-1_8B-Chat",
help="Checkpoint name or path, default to %(default)r",
)
parser.add_argument(
"--cpu-only", action="store_true", help="Run demo with CPU only"
)
parser.add_argument(
"--server-port", type=int, default=8000, help="Demo server port."
)
parser.add_argument(
"--server-name",
type=str,
# default="127.0.0.1",
default="0.0.0.0",
help="Demo server name. Default: 127.0.0.1, which is only visible from the local computer."
" If you want other computers to access your server, use 0.0.0.0 instead.",
)
parser.add_argument("--disable-gc", action="store_true",
help="Disable GC after each response generated.")
args = parser.parse_args()
return args
class EmbeddingRequest(BaseModel):
input: List[str]
model: str
def num_tokens_from_string(string: str) -> int:
"""Returns the number of tokens in a text string."""
encoding = tiktoken.get_encoding('cl100k_base')
num_tokens = len(encoding.encode(string))
return num_tokens
def expand_features(embedding, target_length):
poly = PolynomialFeatures(degree=2)
expanded_embedding = poly.fit_transform(embedding.reshape(1, -1))
expanded_embedding = expanded_embedding.flatten()
if len(expanded_embedding) > target_length:
# 如果扩展后的特征超过目标长度,可以通过截断或其他方法来减少维度
expanded_embedding = expanded_embedding[:target_length]
elif len(expanded_embedding) < target_length:
# 如果扩展后的特征少于目标长度,可以通过填充或其他方法来增加维度
expanded_embedding = np.pad(
expanded_embedding, (0, target_length - len(expanded_embedding))
)
return expanded_embedding
@app.post("/v1/embeddings")
async def get_embeddings(
request: EmbeddingRequest
):
# 计算嵌入向量和tokens数量
embeddings = [embeddings_model.encode(text) for text in request.input]
# 如果嵌入向量的维度不为1536,则使用插值法扩展至1536维度
embeddings = [
expand_features(embedding, 1536) if len(embedding) < 1536 else embedding
for embedding in embeddings
]
# Min-Max normalization 归一化
embeddings = [embedding / np.linalg.norm(embedding) for embedding in embeddings]
# 将numpy数组转换为列表
embeddings = [embedding.tolist() for embedding in embeddings]
prompt_tokens = sum(len(text.split()) for text in request.input)
total_tokens = sum(num_tokens_from_string(text) for text in request.input)
response = {
"data": [
{"embedding": embedding, "index": index, "object": "embedding"}
for index, embedding in enumerate(embeddings)
],
"model": request.model,
"object": "list",
"usage": {
"prompt_tokens": prompt_tokens,
"total_tokens": total_tokens,
},
}
return response
if __name__ == "__main__":
args = _get_args()
tokenizer = AutoTokenizer.from_pretrained(
args.checkpoint_path,
trust_remote_code=True,
resume_download=True,
)
if args.cpu_only:
device_map = "cpu"
else:
device_map = "mps"
model = AutoModelForCausalLM.from_pretrained(
args.checkpoint_path,
device_map=device_map,
trust_remote_code=True,
resume_download=True,
).eval()
embeddings_model = SentenceTransformer('m3e-base', device='cpu')
model.generation_config = GenerationConfig.from_pretrained(
args.checkpoint_path,
trust_remote_code=True,
resume_download=True,
)
uvicorn.run(app, host=args.server_name, port=args.server_port, workers=1)启动:
python3 openai_api.py
第一次运行会下载模型文件,并使用一些Python库,如果报错直接pip3下载即可。文件包含了大量的Python库使用,缺少的话直接pip3下载。
成功运行会创建本地链接,发起标准请求即可访问,请求内容为:
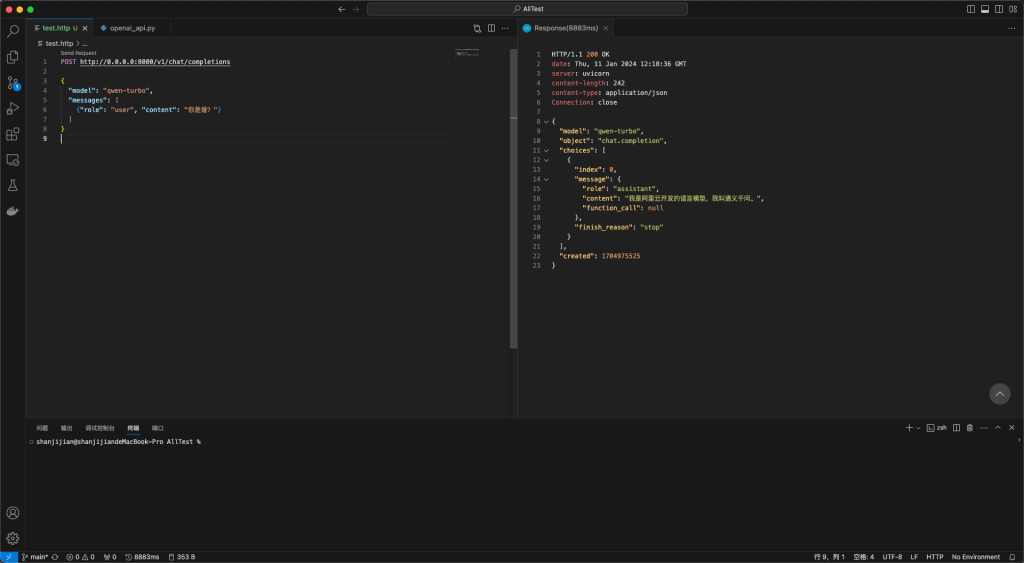
POST http://0.0.0.0:8000/v1/chat/completions
{
"model": "qwen-turbo",
"messages": [
{"role": "user", "content": "你是谁?"}
]
}
这样我们的通义千问-1.8B搭建及使用就完成了。
One API 搭建及使用
访问链接:https://github.com/songquanpeng/one-api
要求
- x64系统(Mac的M芯片用户可以使用OrbStack软件模拟Ubuntu x64系统)
- Docker环境
开始搭建
直接使用Docker进行搭建,官方建议并发量较大使用MySQL 模式部署,我们测试的话直接使用SQLite 模式部署即可。
docker run --name one-api -d --restart always -p 3001:3000 -e TZ=Asia/Shanghai -v /home/ubuntu/data/one-api:/data justsong/one-api因为后续FastGPT默认为3000端口,这里我们使用3001端口部署。启动完成后使用该端口即可访问。
点击渠道-添加新的渠道,按照图里的方式进行填写。
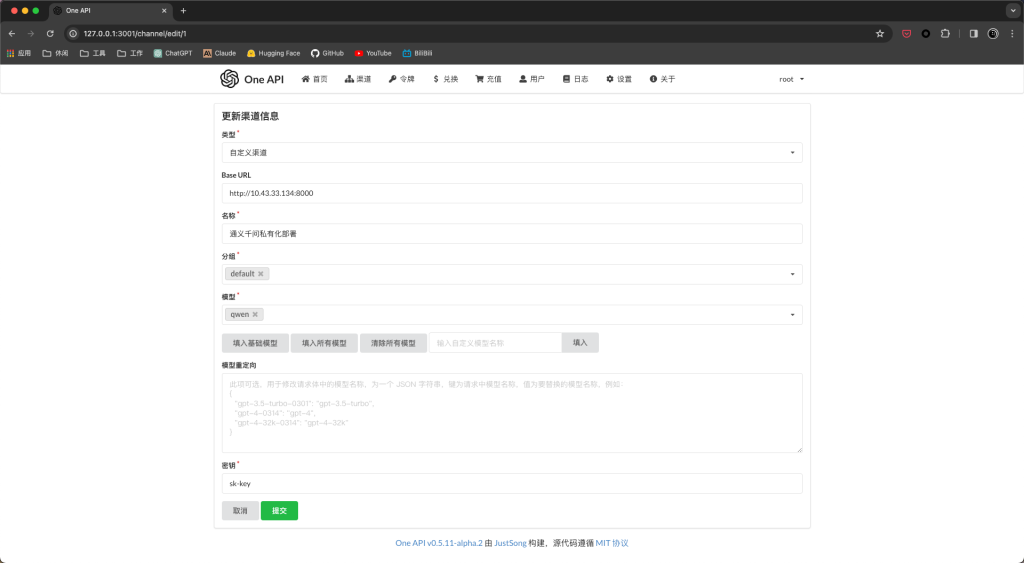
图中的Base URL为本机地址的8000端口,完成后点提交,渠道页面点击测试,在模型界面会收到请求,One API 页面会产生一条报错,适配问题忽略即可。

点击令牌-添加新的令牌,按照图中方式填写,添加完成后点击复制,将生成的令牌密钥保存备用。
另外为了解决知识库向量化的问题,我们搭建m3e对接在One API上,方法如下。
Docker下载并启动m3e:
docker pull registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api
docker run -d -p 6008:6008 registry.cn-hangzhou.aliyuncs.com/fastgpt_docker/m3e-large-api启动完成后在One API渠道-添加新的渠道界面,按照图里的方式进行填写。
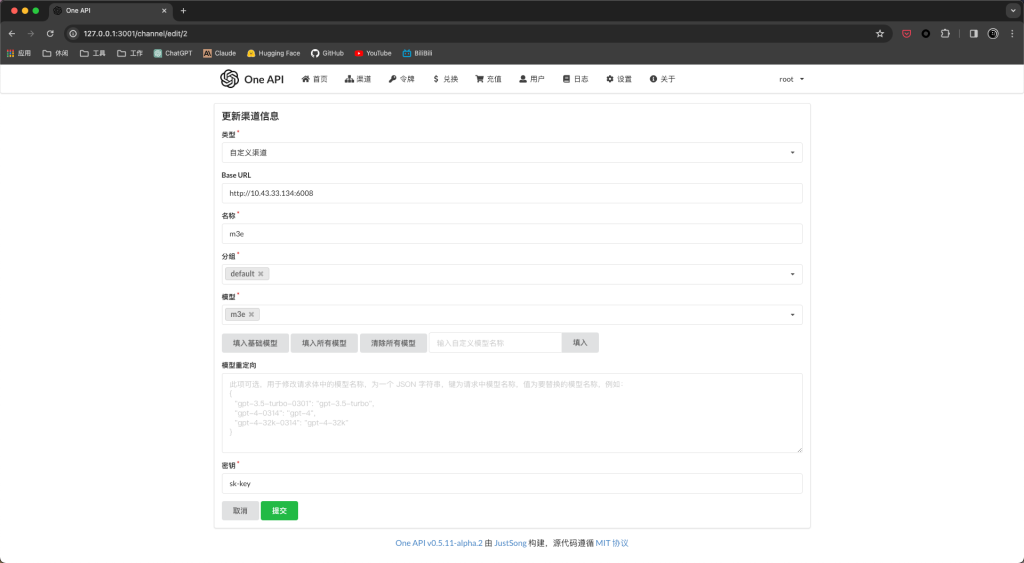
点击测试,使用命令:docker logs -f 容器ID查看Docker容器中m3e日志,发现收到请求。
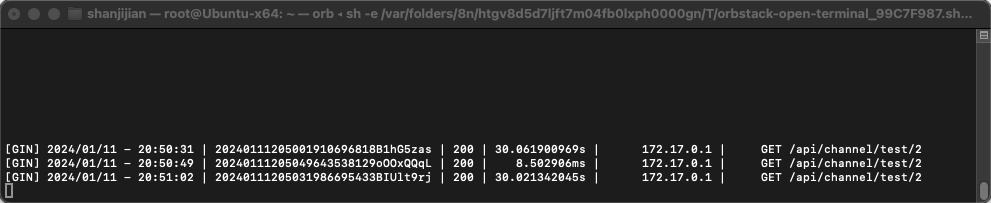
至此,One API的搭建就完成了。
FastGPT搭建及使用
访问链接:https://github.com/labring/FastGPT
要求
- Docker环境
- docker-compose环境
开始搭建
使用docker-compose进行搭建,依次执行命令:
mkdir fastgpt
cd fastgpt
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/files/deploy/fastgpt/docker-compose.yml
curl -O https://raw.githubusercontent.com/labring/FastGPT/main/projects/app/data/config.json
docker-compose pull修改docker-compose.yml文件内容,OPENAI_BASE_URL为One API地址后加v1,CHAT_API_KEY为令牌密钥,如果你是Mac的M芯片用户,无法用 mongo5,需要换成 mongo4.x,完整的配置文件如下:
# 非 host 版本, 不使用本机代理
version: '3.3'
services:
pg:
image: ankane/pgvector:v0.5.0 # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/pgvector:v0.5.0 # 阿里云
container_name: pg
restart: always
ports: # 生产环境建议不要暴露
- 5432:5432
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- POSTGRES_USER=username
- POSTGRES_PASSWORD=password
- POSTGRES_DB=postgres
volumes:
- ./pg/data:/var/lib/postgresql/data
mongo:
image: mongo:4.4.26
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/mongo:5.0.18 # 阿里云
container_name: mongo
restart: always
ports: # 生产环境建议不要暴露
- 27017:27017
networks:
- fastgpt
environment:
# 这里的配置只有首次运行生效。修改后,重启镜像是不会生效的。需要把持久化数据删除再重启,才有效果
- MONGO_INITDB_ROOT_USERNAME=username
- MONGO_INITDB_ROOT_PASSWORD=password
volumes:
- ./mongo/data:/data/db
fastgpt:
container_name: fastgpt
image: ghcr.io/labring/fastgpt:latest # git
# image: registry.cn-hangzhou.aliyuncs.com/fastgpt/fastgpt:latest # 阿里云
ports:
- 3000:3000
networks:
- fastgpt
depends_on:
- mongo
- pg
restart: always
environment:
# root 密码,用户名为: root
- DEFAULT_ROOT_PSW=1234
# 中转地址,如果是用官方号,不需要管
- OPENAI_BASE_URL=http://10.43.33.134:3001/v1
- CHAT_API_KEY=sk-0coE8H45zHvKRmqS325e847f7fF246729c65273cF7C957Be
- DB_MAX_LINK=5 # database max link
- TOKEN_KEY=any
- ROOT_KEY=root_key
- FILE_TOKEN_KEY=filetoken
# mongo 配置,不需要改. 如果连不上,可能需要去掉 ?authSource=admin
- MONGODB_URI=mongodb://username:password@mongo:27017/fastgpt?authSource=admin
# pg配置. 不需要改
- PG_URL=postgresql://username:password@pg:5432/postgres
volumes:
- ./config.json:/app/data/config.json
networks:
fastgpt:修改config.json文件,添加qwen模型和m3e,完整的配置文件如下:
{
"SystemParams": {
"pluginBaseUrl": "",
"vectorMaxProcess": 15,
"qaMaxProcess": 15,
"pgHNSWEfSearch": 100
},
"ChatModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"price": 0,
"maxContext": 16000,
"maxResponse": 4000,
"quoteMaxToken": 2000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-3.5-turbo-16k",
"name": "GPT35-16k",
"maxContext": 16000,
"maxResponse": 16000,
"price": 0,
"quoteMaxToken": 8000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-4",
"name": "GPT4-8k",
"maxContext": 8000,
"maxResponse": 8000,
"price": 0,
"quoteMaxToken": 4000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "qwen",
"name": "qwen",
"maxContext": 8000,
"maxResponse": 8000,
"price": 0,
"quoteMaxToken": 4000,
"maxTemperature": 1.2,
"censor": false,
"vision": false,
"defaultSystemChatPrompt": ""
},
{
"model": "gpt-4-vision-preview",
"name": "GPT4-Vision",
"maxContext": 128000,
"maxResponse": 4000,
"price": 0,
"quoteMaxToken": 100000,
"maxTemperature": 1.2,
"censor": false,
"vision": true,
"defaultSystemChatPrompt": ""
}
],
"QAModels": [
{
"model": "gpt-3.5-turbo-16k",
"name": "GPT35-16k",
"maxContext": 16000,
"maxResponse": 16000,
"price": 0
}
],
"CQModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"maxContext": 16000,
"maxResponse": 4000,
"price": 0,
"functionCall": true,
"functionPrompt": ""
},
{
"model": "gpt-4",
"name": "GPT4-8k",
"maxContext": 8000,
"maxResponse": 8000,
"price": 0,
"functionCall": true,
"functionPrompt": ""
}
],
"ExtractModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"maxContext": 16000,
"maxResponse": 4000,
"price": 0,
"functionCall": true,
"functionPrompt": ""
}
],
"QGModels": [
{
"model": "gpt-3.5-turbo-1106",
"name": "GPT35-1106",
"maxContext": 1600,
"maxResponse": 4000,
"price": 0
}
],
"VectorModels": [
{
"model": "text-embedding-ada-002",
"name": "Embedding-2",
"price": 0.2,
"defaultToken": 700,
"maxToken": 3000
},
{
"model": "m3e",
"name": "m3e",
"price": 0.2,
"defaultToken": 700,
"maxToken": 3000
}
],
"ReRankModels": [],
"AudioSpeechModels": [
{
"model": "tts-1",
"name": "OpenAI TTS1",
"price": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"WhisperModel": {
"model": "whisper-1",
"name": "Whisper1",
"price": 0
}
}启动:
docker-compose up -d使用3000端口即可访问FastGPT页面,点击应用-新建应用,创建一个简单对话应用,AI模型选择qwen,与其对话。
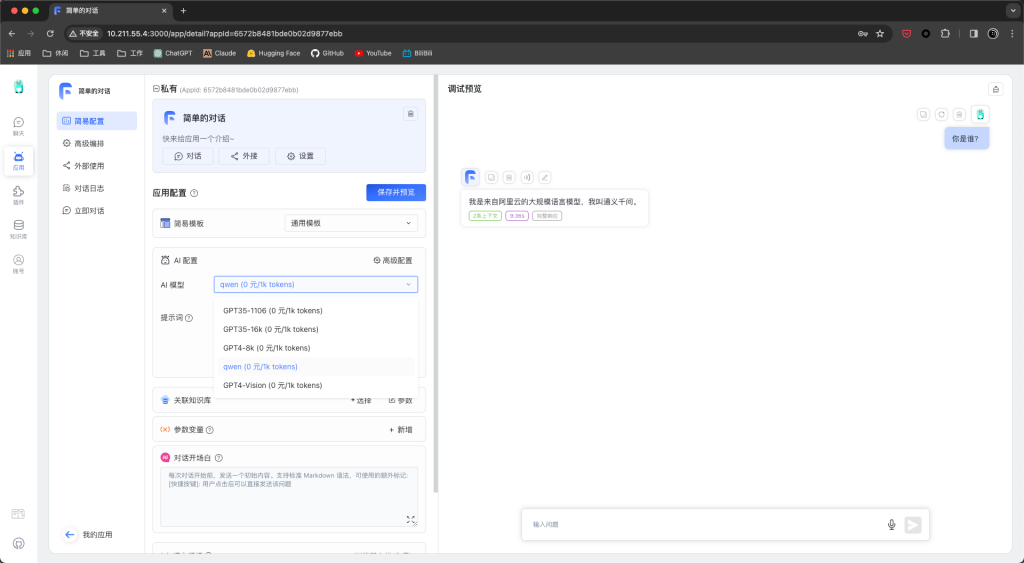
表明qwen模型成功对接。接下来点击知识库-新建-知识库,索引模型选择m3e,确认创建。
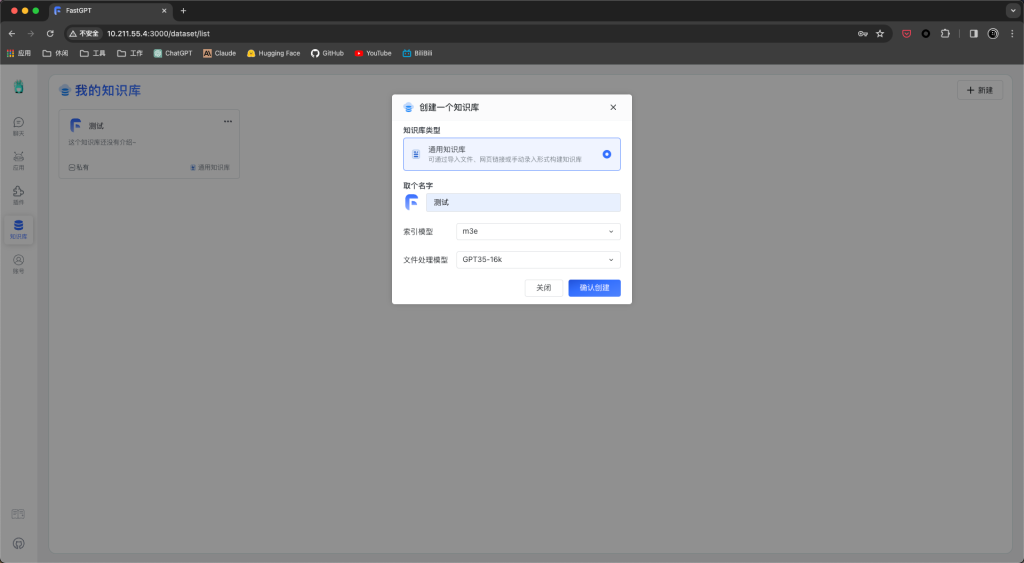
手动录入一条你想添加的内容,例如:
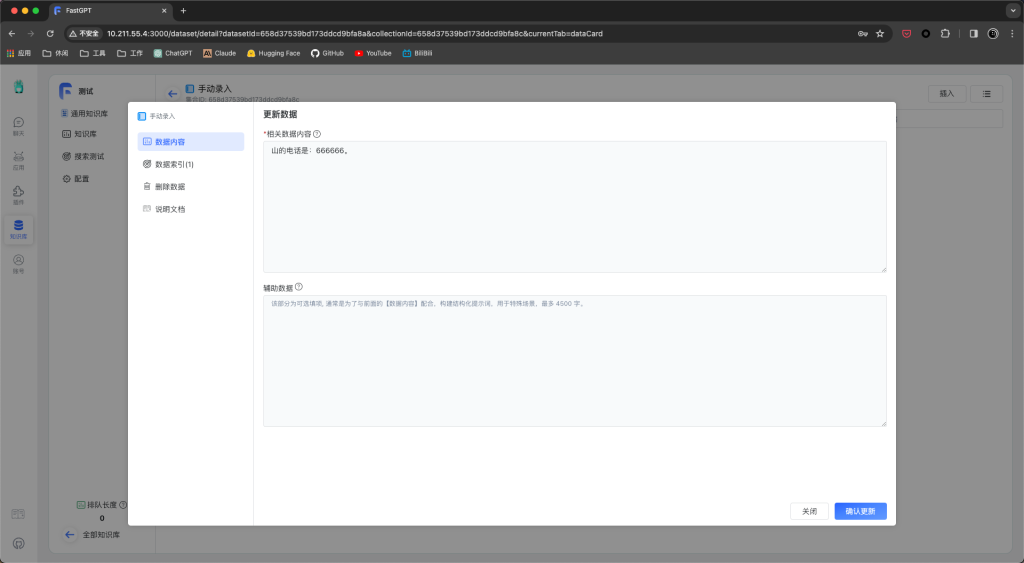
回到应用,点击新建应用,选择知识库模版,创建。完成进入,AI模型选择qwen,关联知识库选择刚刚创建的知识库,提问。
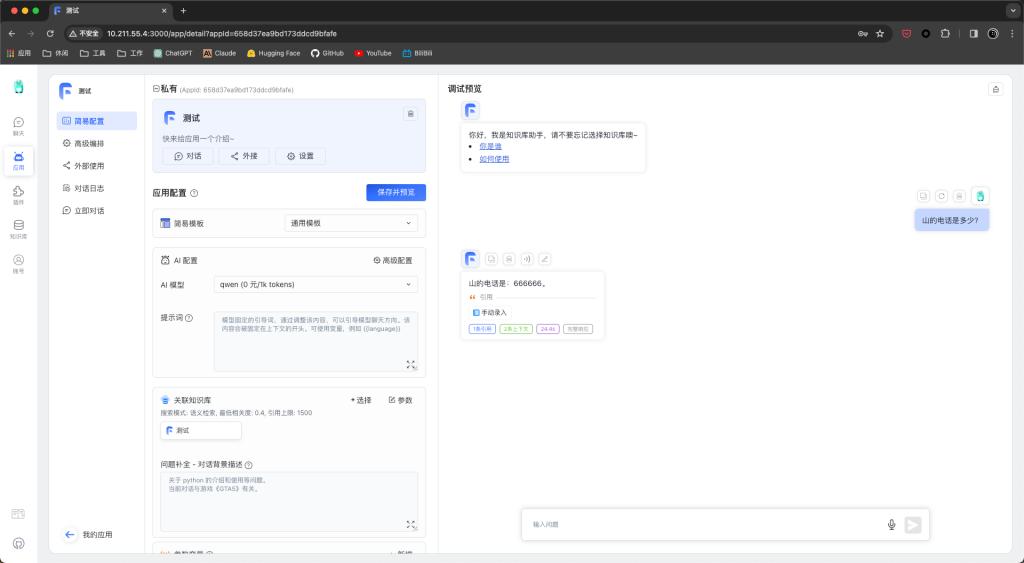
恭喜你,搭建完成。
大模型已经彻底改变了我们的生活,搜索平台被语言大模型替代,内容资讯大量由AI生成。
虽然效果最佳的ChatGPT为闭源开发,但现在仍是最好的开源时代。
参考链接:
发表回复